参考文献
本記事は次の論文を参考にして書かれています。
フィルトレーションとパーシステントホモロジー
フィルトレーションが入った位相空間にパーシステントホモロジーが定義できることを見ます。
フィルトレーションとは
位相空間 の部分集合の列
をフィルトレーションと言います。
添字の大小と包含関係が必ずしも一致している必要はありません。また添字集合は整数だけではなく実数で考えることもできます。
パーシステントホモロジー
次のような単体複体のフィルトレーションに対して、1次のホモロジーを考えていきます。
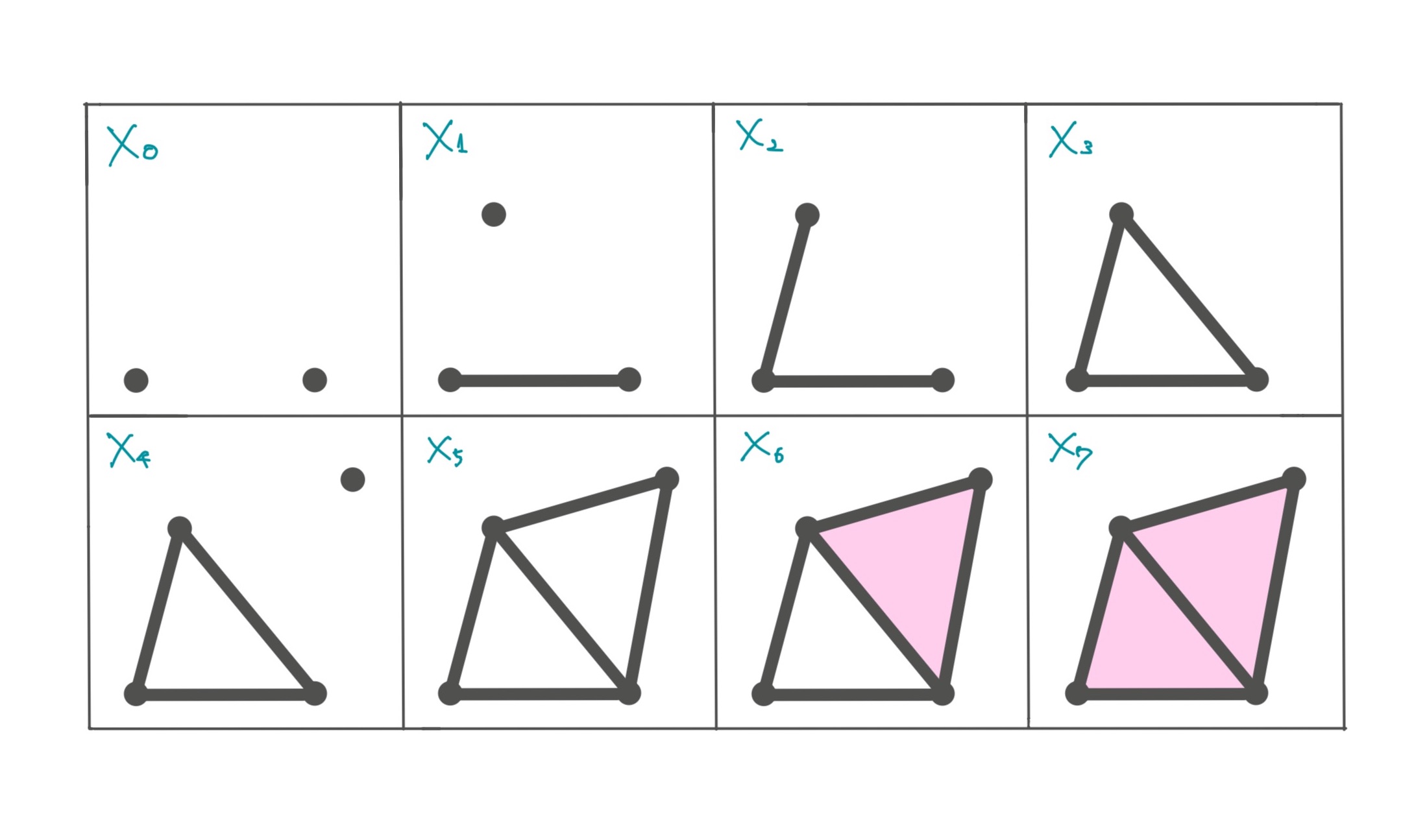
1次のホモロジーを考えるというのは、1次元の穴を考えるということです。フィルトレーションにおける穴の様子をまとめると次のようになります。
- で1つめの穴ができる
- で2つめの穴ができる
- で2つめの穴が埋まる
- で1つめの穴が埋まる
したがってこのフィルトレーションに対する1次のパーシステント図は以下のようになります。
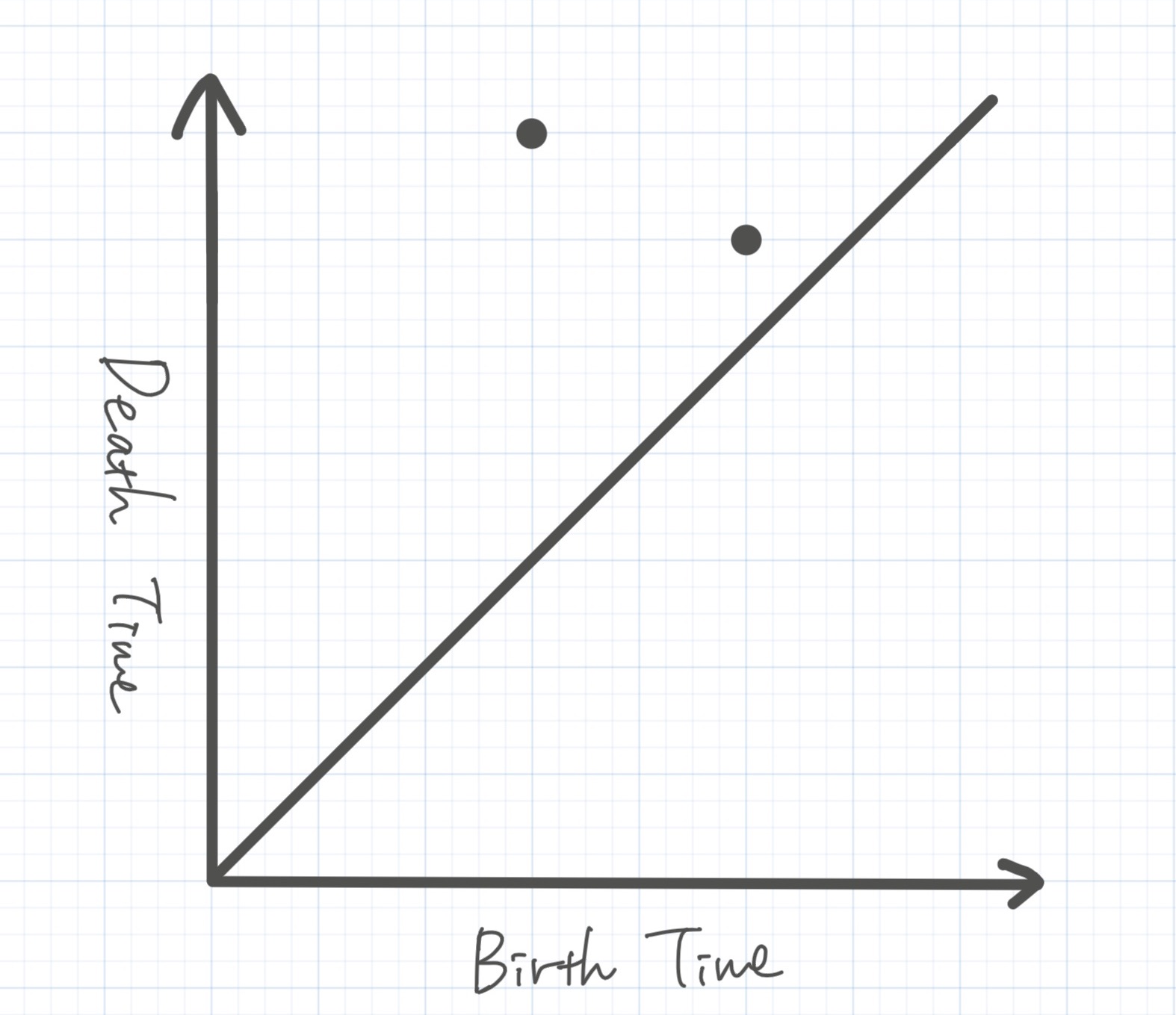
次は0次のホモロジーを考えてみます。
- で連結成分が2つできる
- で連結成分が1つ吸収されると同時に、別に1つできる
- で1つ吸収される
- 以降は連結成分は1つのまま
以上から、フィルトレーション内で発生した連結成分は延べ3つです。0次のパーシステント図は以下のようになります。
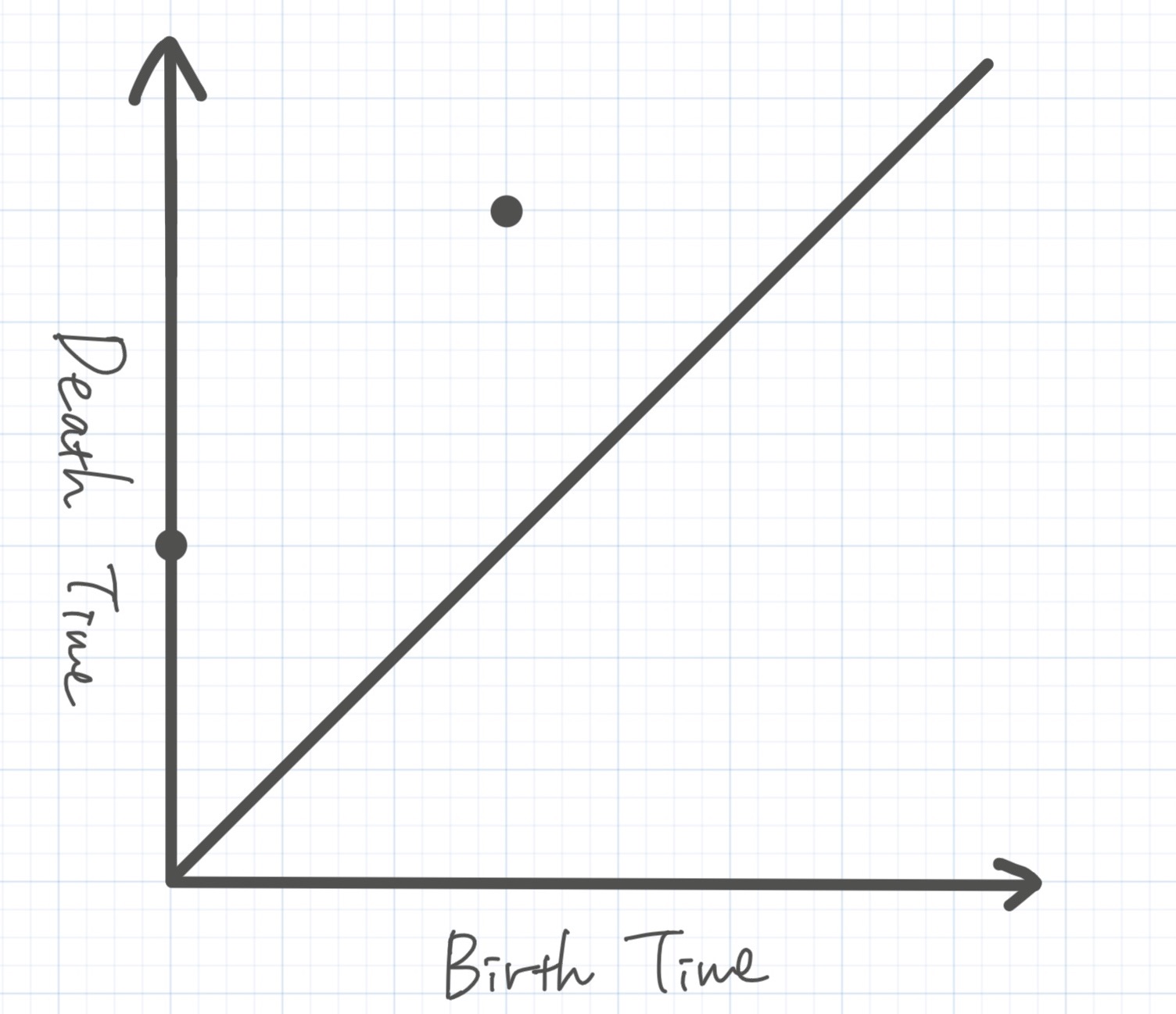
連結成分の延べ数は3なのに、パーシステント図内の点は2つだけです。これはなぜかというと、 で発生した連結成分が最後まで生き残っているからです。したがって消滅(吸収)時刻が という扱いになり、パーシステント図内に表現できません。
パーシステント図にはこのような欠点があるため、バーコードという図が利用されることもあります。今回の例で0次のバーコードを書くと次のようになります。
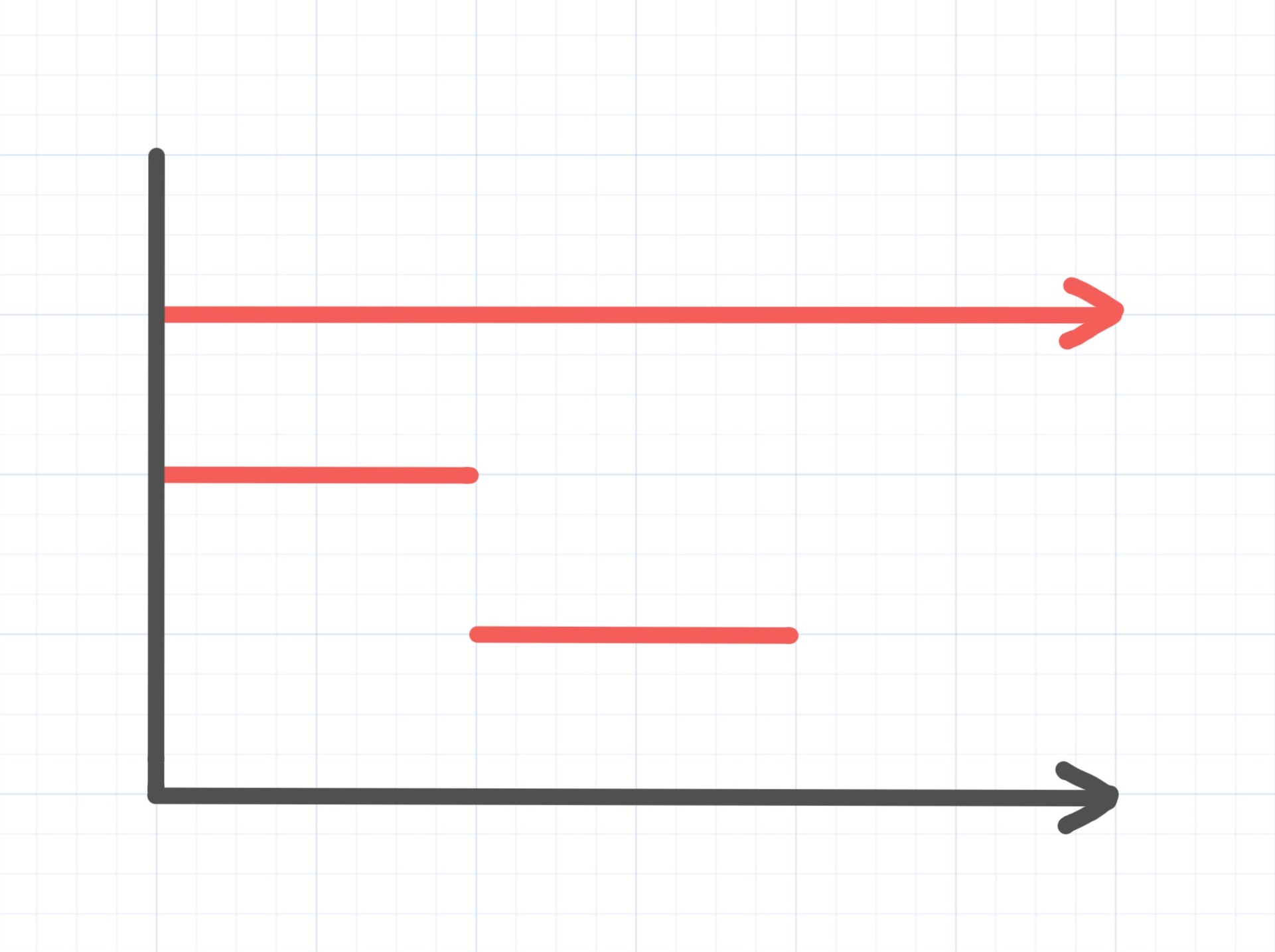
バーコードは、発生時刻と消滅時刻を両端とする線分の集まりとして表現されます。消滅時刻を持たないものは、それを表すために矢印で描かれます。
こんなふうに、位相空間にフィルトレーションが定義されていれば、パーシステントホモロジーを考えることができます。
クラスタリング
フィルトレーションからパーシステントホモロジーが定義されることを見てきました。ここからは、パーシステントホモロジーを使ってクラスタリングするアイデアを解説していきます。
何をもってクラスタとするか
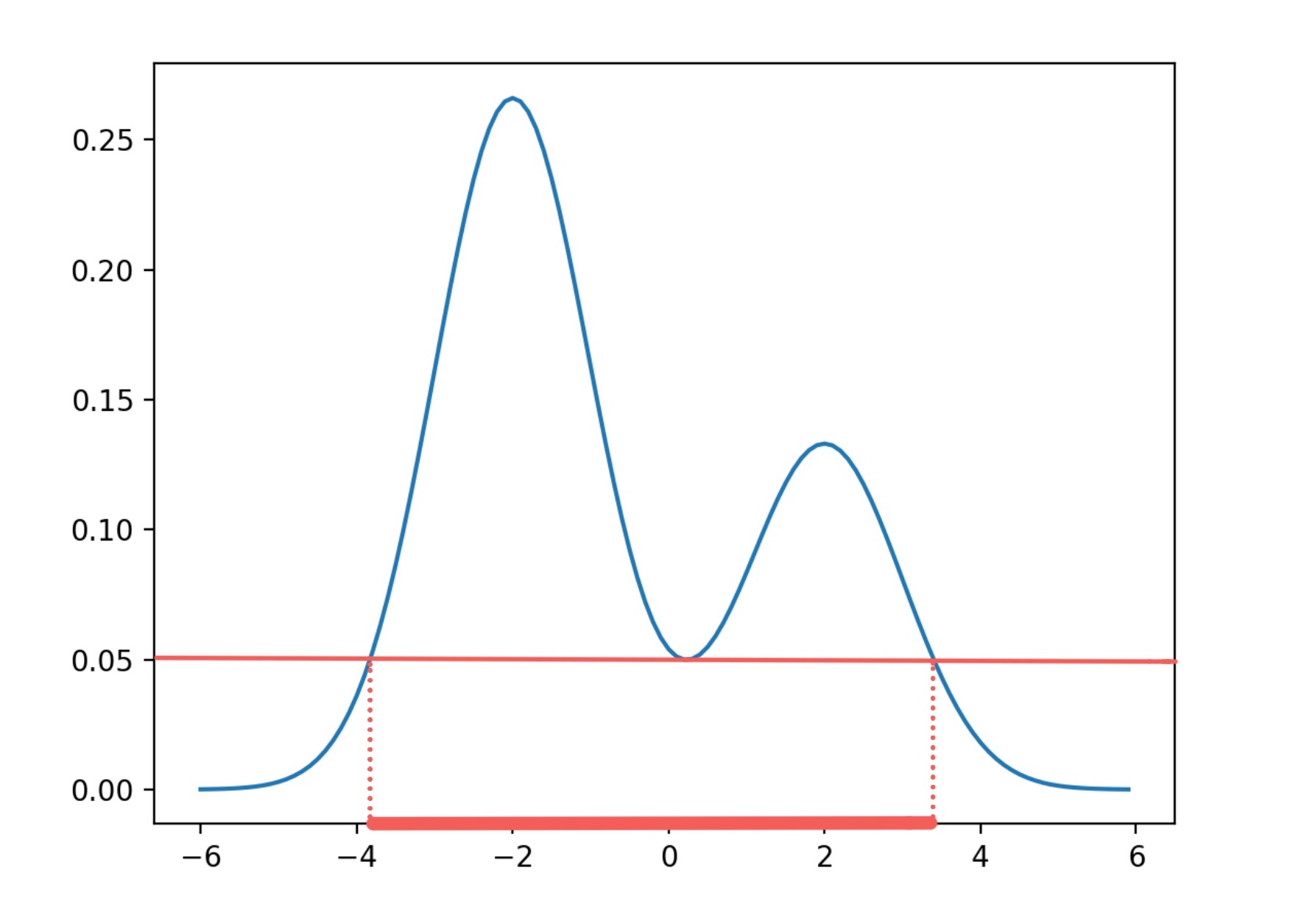
とある確率分布から得られたサンプルをヒストグラムとして表してみました。クラスタはいくつあるでしょうか?
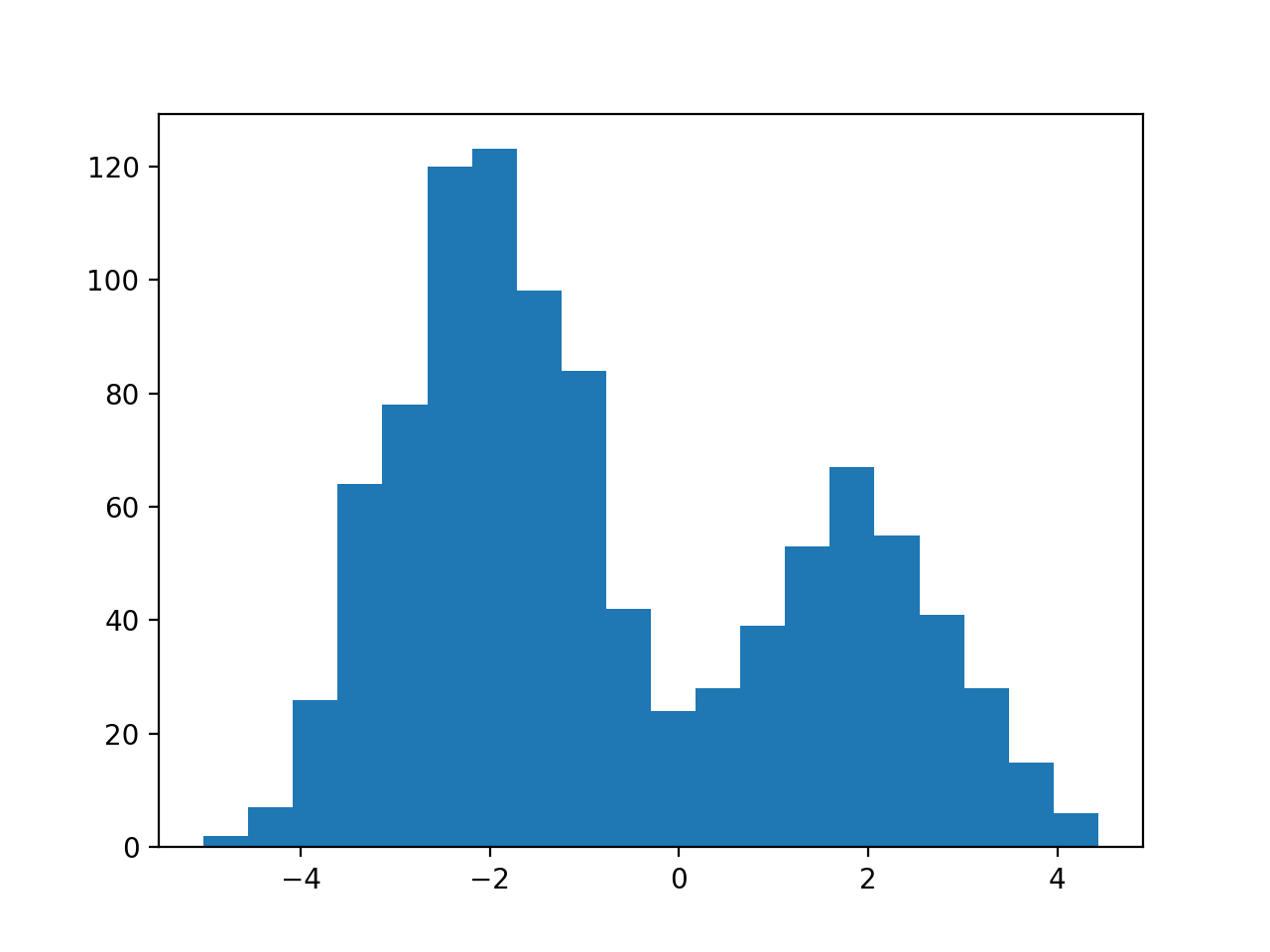
人間の目には2つに見えますね。このヒストグラムは次のような混合正規分布からサンプルしたものです。当たり前ですがヒストグラムと似たような形になりますね。確率密度関数のグラフを見ても、クラスタは2つに見えます。
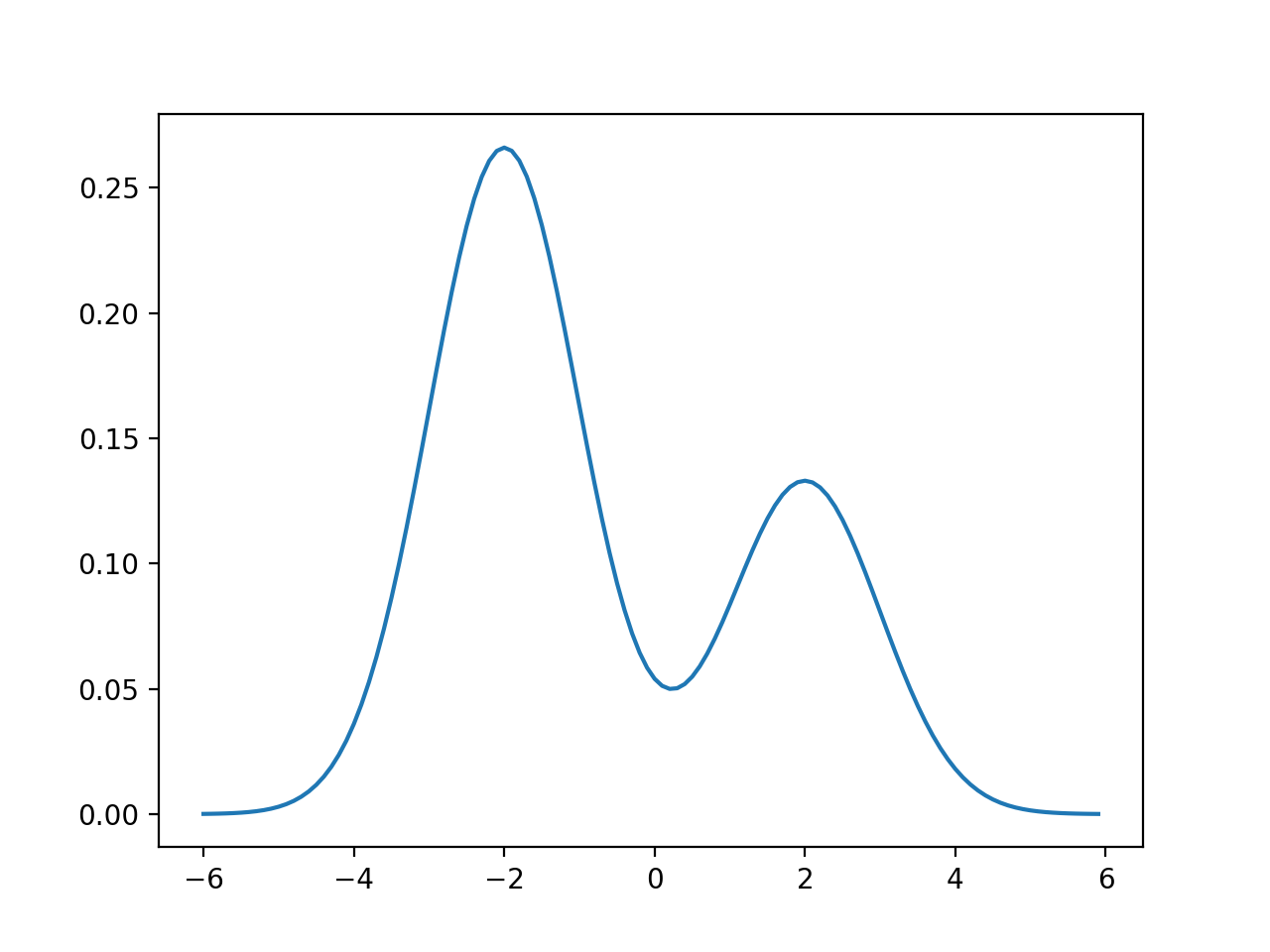
なにをもってクラスタと呼んでいるのかと言えば、グラフの山の数です。つまりグラフの山の数を数えることができれば、クラスタリングができるということです。
パーシステントホモロジーでクラスタを捕える
を確率密度関数とします。 の部分集合 を と定義します。すると部分集合族 はフィルトレーションをなします。 に対して なので、上で挙げた例とは添字と部分集合の関係が逆になっていることに注意です。
さて、フィルトレーションを定義したのでパーシステントホモロジーを考えることができます。
クラスタリングというのはデータ点がかたまって存在する場所を探すタスクです。したがって連結成分だけ見ればいいですね。
上の混合正規分布を例に、フィルトレーション内で連結成分がどのように移り変わっていくかを見ていきます。
が十分多きいとき、確率密度関数のグラフを見てわかるように です。
くらいまで小さくしてみましょう。 は空集合ではなくなり、下図のように連結成分を1つもちます。
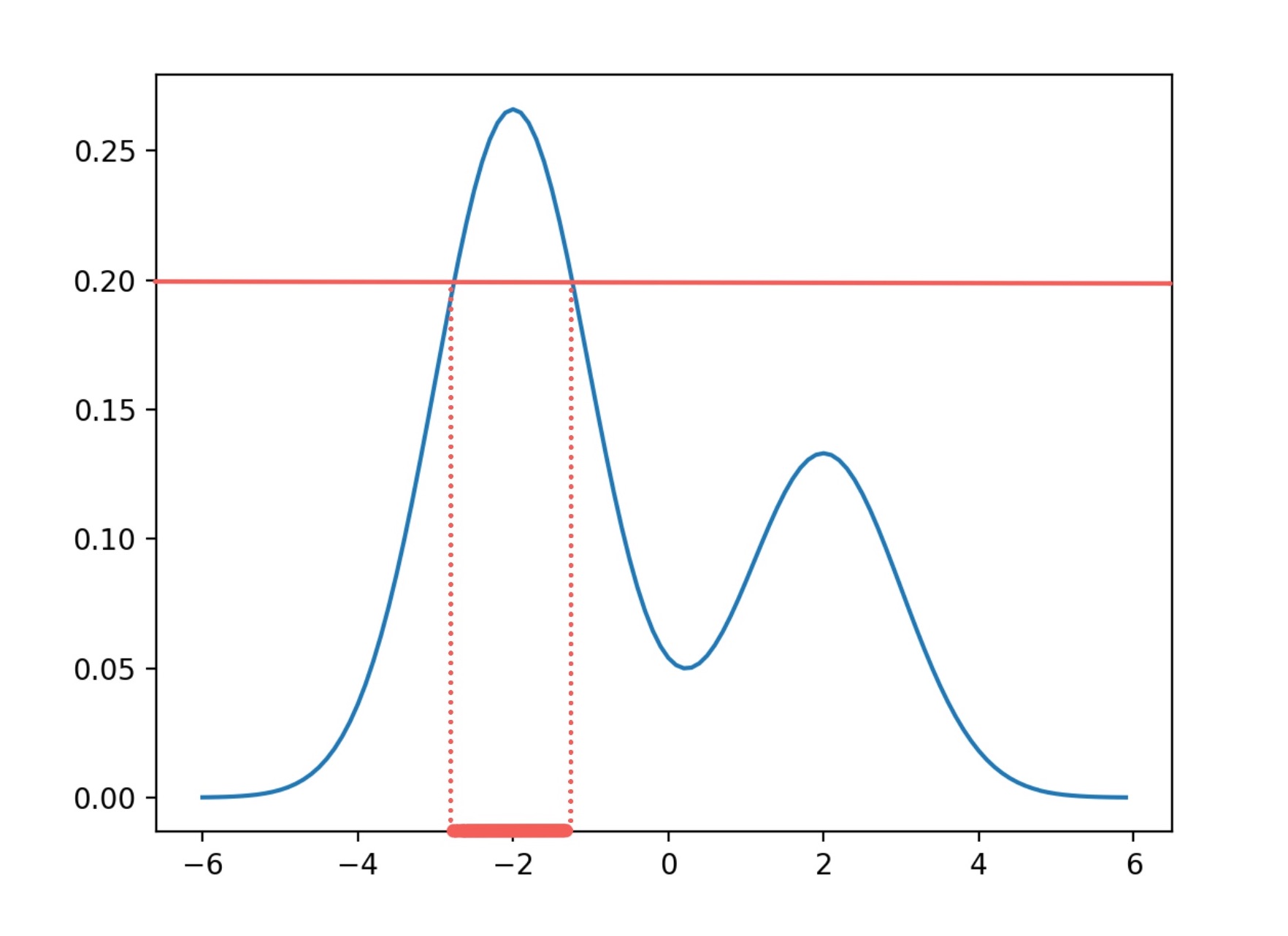
は連結成分が2つになりました。
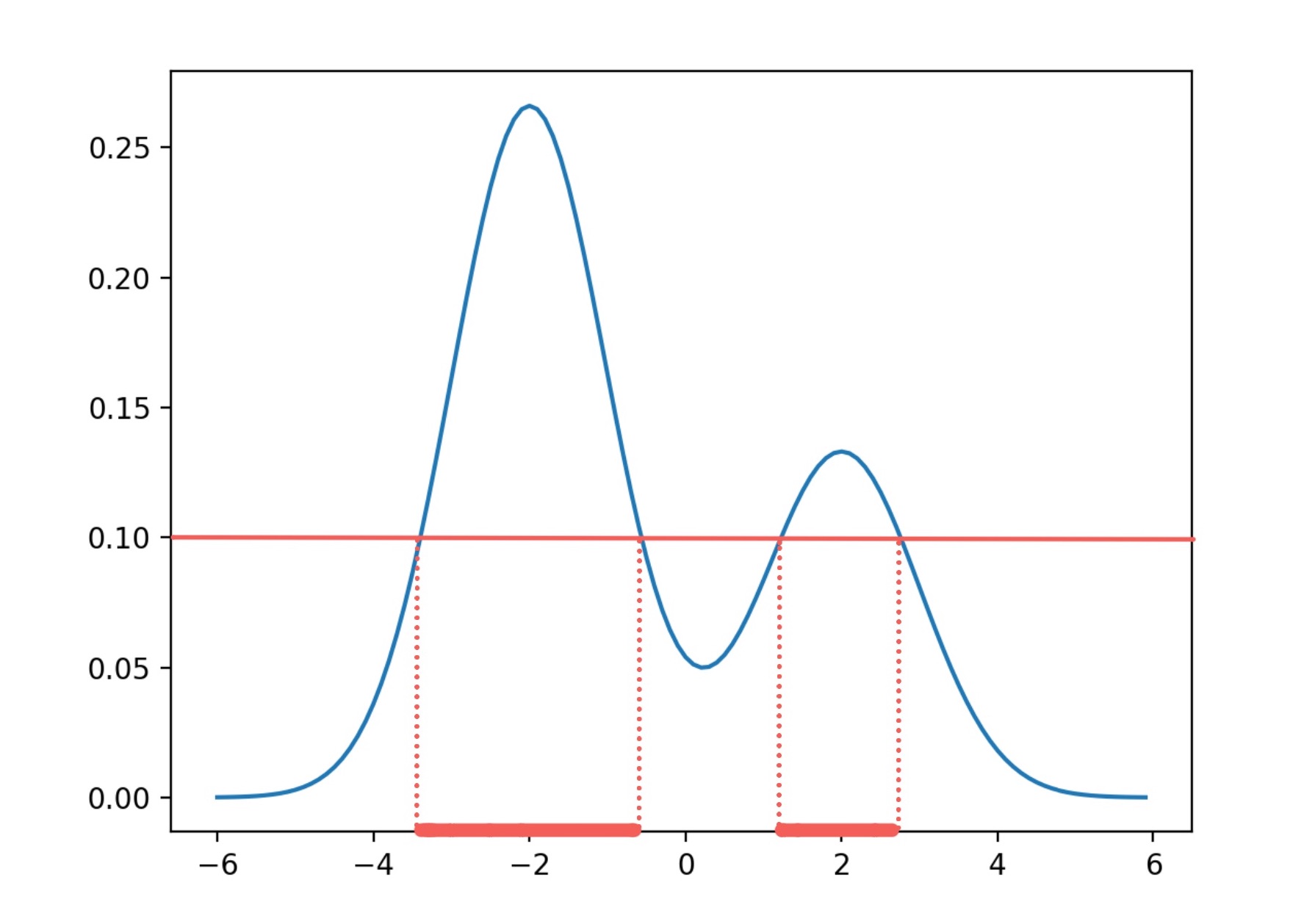
ちょうど のタイミングで、さっきまで2つあった連結成分が融合して1つになりました。これ以降は をどれだけ小さくしても連結成分は1つのままです。
バーコードは次のようになります。
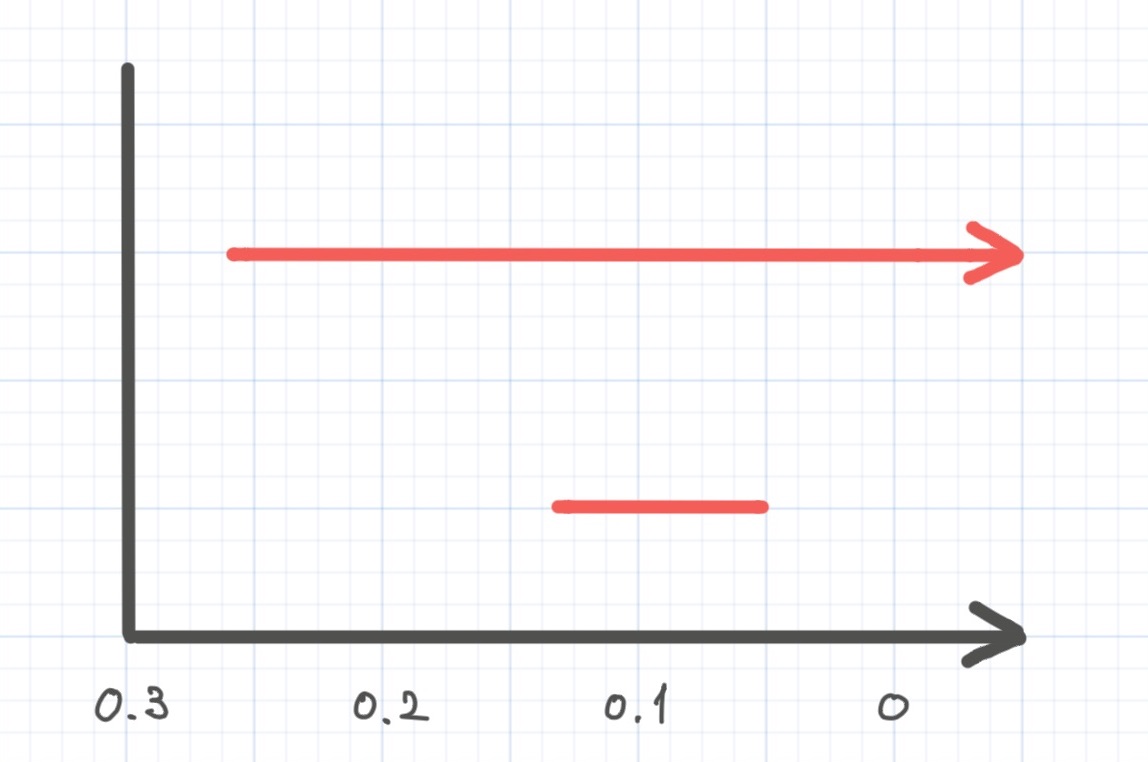
バーコードにおける線分の本数がクラスタの数に一致しています。
さて、次はこのような確率分布に対して考えてみます。これはさっきの混合正規分布に正弦波のノイズを加えたものです。ノイズがあったとしても、クラスタは2つあるように見えますね。
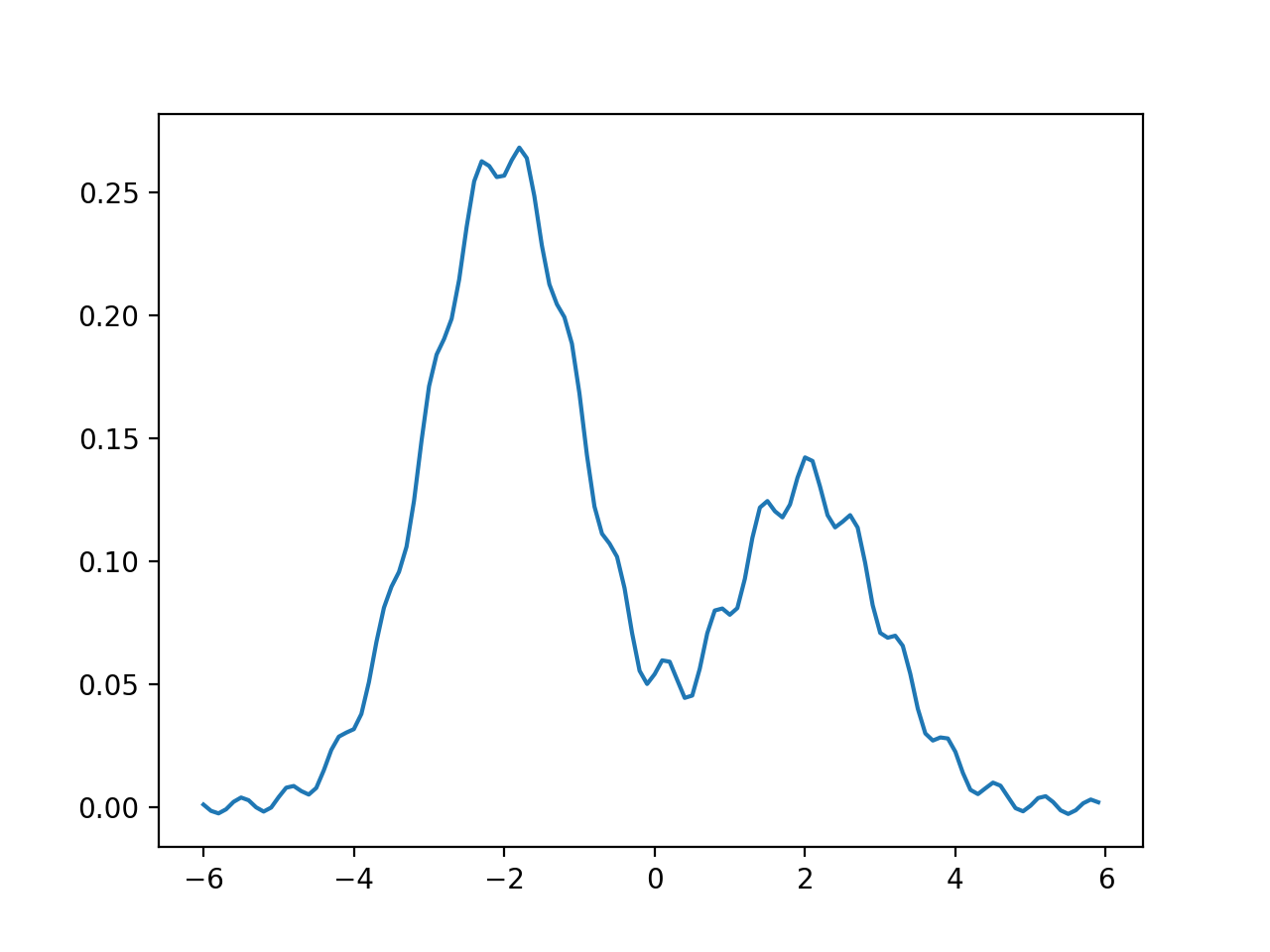
上と同様のフィルトレーションを考えると、バーコードは以下のようになります。
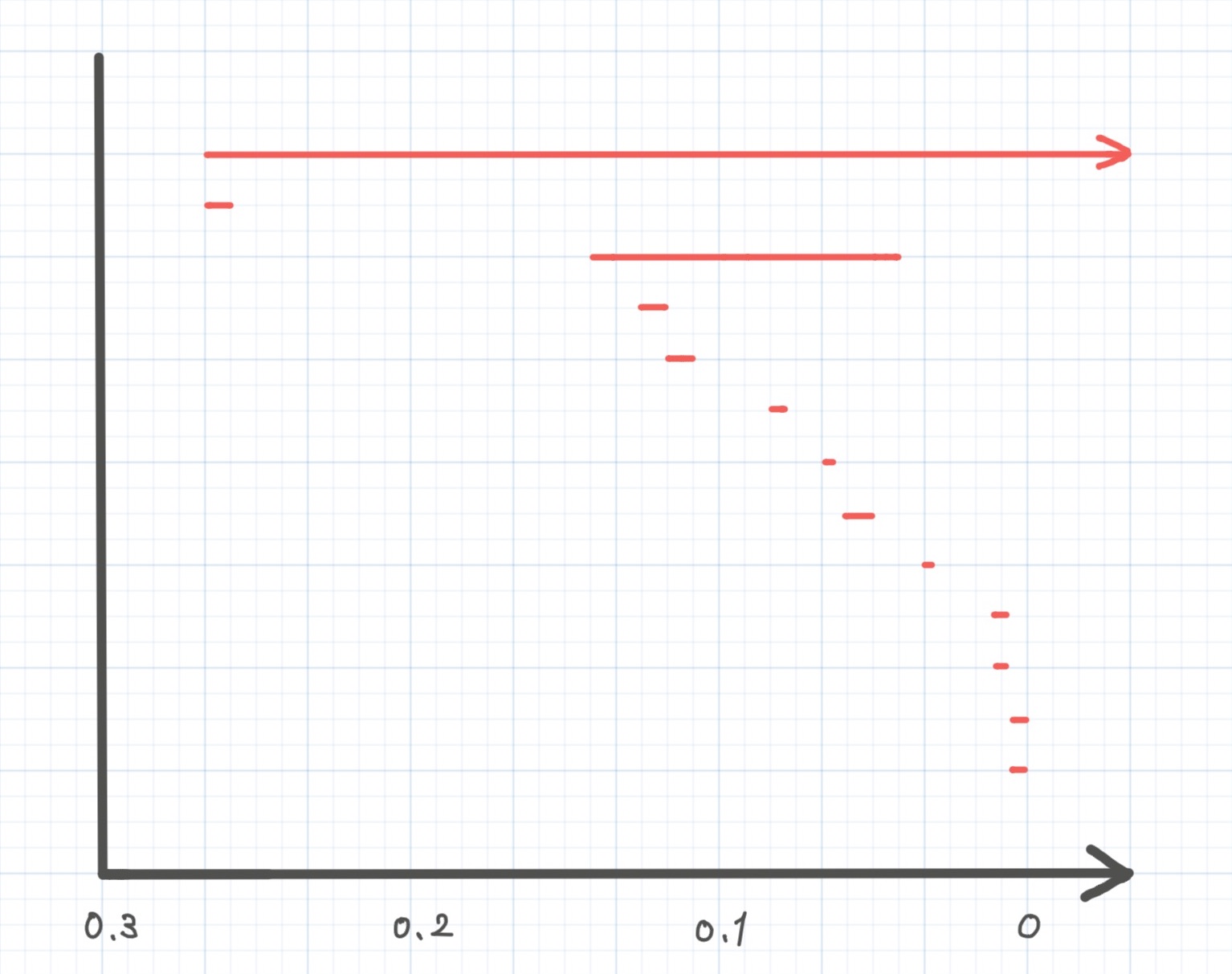
さっきとは違ってバーコードの本数がクラスタ数よりも多くなってしまっています。それもそのはずで、実はパーシステントホモロジーは確率密度関数の極大値の個数を数えているからです。
クラスタリングをするにはノイズを無視して大きな山を数える必要があります。大きな山というのは、バーコードで言えば長い線分のことです。実際、長いバーコードはちょうど2本あります。
しかし「長い」という概念は少々曖昧です。どこからが長く、どこからが短いのでしょうか。これはどれほど細かくクラスタリングするのかという要件に依存するところです。
今回の例のように、ノイズとクラスタがはっきり区別できる状況であればあまり悩むことはないかもしれません。しかし実際はそんなことも多くないでしょう。その場合はバーコードと実データを照らし合わせながら妥当なクラスタ数を吟味する必要がありそうです。
まとめ
パーシステントホモロジーを使ってクラスタリングする方法を紹介しました。ほかのクラスタリング手法と違うことは、クラスタ数を予め与える必要がないことです。このアルゴリズムでは長いバーコードの本数としてクラスタ数を出力してくれます。尤も、クラスタ数の妥当性は人間が判断しなければならないでしょうが。