状況設定
手元に 1 枚のコインがあるとします。このコインの表の出る確率が知りたいとしましょう。例えばサッカーの公式試合のコイントスに利用したいけど、表と裏の出やすさに偏りがあると困る、みたいな場合です。まあそんな状況でベイズ推論を使おうとする人なんていないでしょうけれど。
さて、このコインを独立に N 回投げたところ、n 回だけ表が出ました。このデータをもとに、コインの表の出る確率を推論していきます。
事前分布
表の出る確率 q の事前分布はベータ分布 Beta(q∣a,b) とします。
次に尤度関数のほうをモデリングしていくわけですが、2 通りの方法を試してみましょう。
二項分布でモデリング
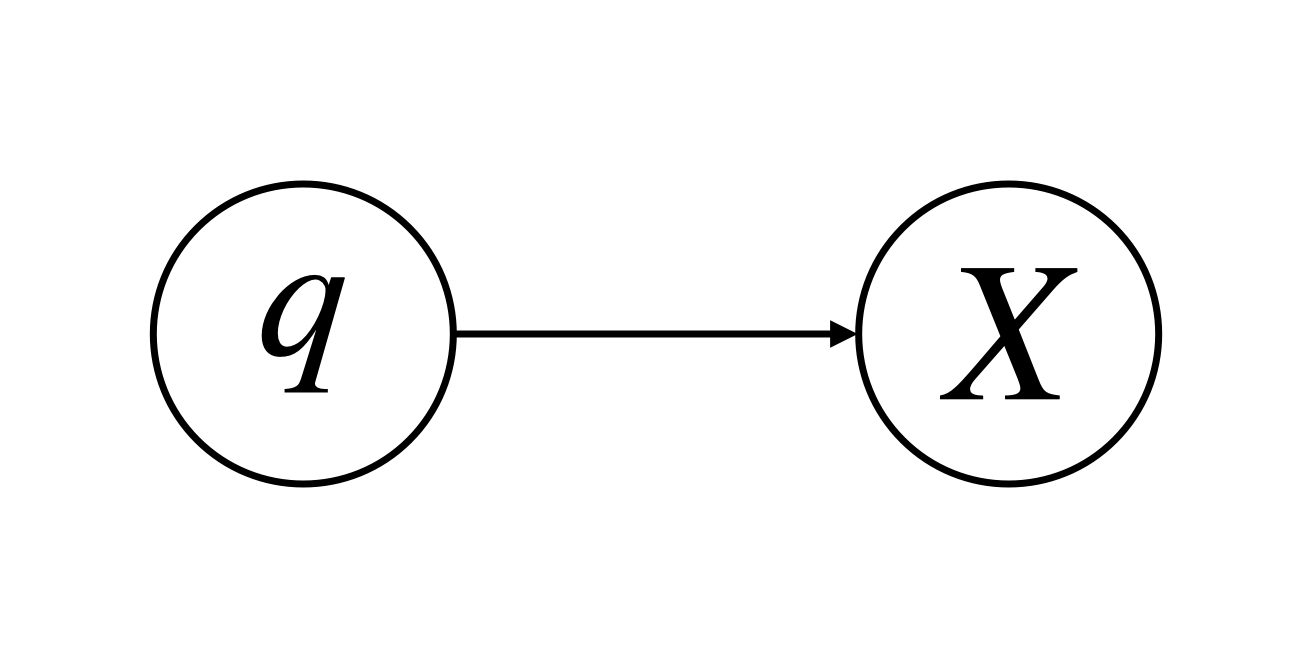
まずは二項分布 Binom(X∣N,q) でモデリングしてみます。つまり、手元のデータは二項分布から得られた一つの標本だと考えるわけです。事前分布とあわせてグラフィカルモデルで表現すると以下のようになります。
必要なものは揃ったので、事後分布を計算していきましょう。チルダは定数倍を除いて等しいこと表しています。
p(q∣X)=p(X)p(X∣q)p(q)∼p(X∣q)p(q)∼Binom(X∣N,q)⋅Beta(q∣a,b)=(nN)qn(1−q)N−n⋅B(a,b)−1qa−1(1−q)b−1∼qa+n−1(1−q)b+N−n−1∼Beta(a+n,b+N−n)
事後分布もベータ分布になりましたね。事前分布と比べると、第一パラメータに表の出た回数が、第二パラメータに裏の出た回数が足されました。
ベルヌーイ分布でモデリング
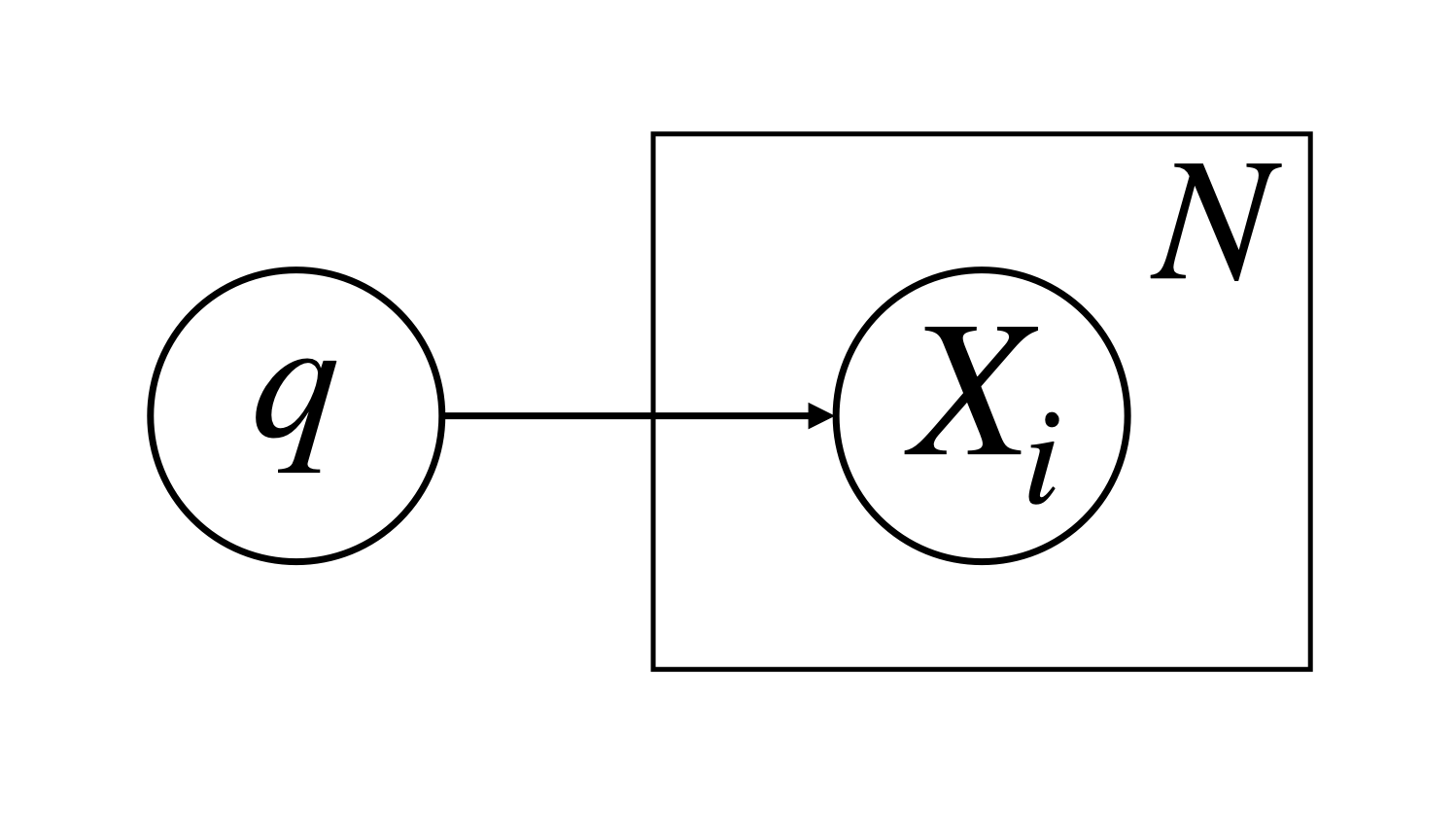
次にベルヌーイ分布 Bern(Xi∣q) でモデリングしてみます。つまり、手元のデータはベルヌーイ分布から得られた N 個の標本だと考えるわけです。事前分布とあわせてグラフィカルモデルで表現すると以下のようになります。
こちらも事後分布の計算をしていきますが、N 個のデータを {Xi} のように集合の記法を用いて表しています。
p(q∣{Xi})∼i∏p(Xi∣q)⋅p(q)=i∏Bern(Xi∣q)⋅Beta(q∣a,b)∼qn(1−q)N−n⋅qa−1(1−q)b−1∼Beta(a+n,b+N−n)
というわけで二項分布でモデリングした場合と同様の事後分布が得られました。
まとめ
二項分布でモデリングするか、ベルヌーイ分布の積でモデリングするかの違いは、組み合わせで考えるか順列で考えるかの違いに似てますね。当然二項分布でモデリングするほうが尤度そのものは大きくなります。しかし事後分布に与える情報量としてはどちらでモデリングしても変わらないということなのでした。